High-Level Architecture
![]()
Agents KIT
Architecture for federated queries over the whole data space.
For more information see
- Our Adoption guideline
- The ARC42 documentation
- An API specification
- The Ontology modelling guide
- The Layers & Modules Architecture
- Our Reference Implementation
- The Deployment guide
Compute-To-Data
This KIT describes a semantically-driven and state-of-the-art compute-to-data architecture for automotive use cases (and beyond), the so-called Knowledge Agents (KA) approach.
It builds on well-established standards and best practices around GAIA-X, W3C and Big Data in order to empower powerful queries to the data space (Skills). Those Skills can be used to answer business questions directly (comparable to a search engine) or they can be embedded in apps to include query results (Knowledge) into workflows with more advanced visualization etc.
To reach this aim, full semantic integration, search and query with focus on relations between entities and data sovereignty is focused. In contrast to a simple file-based data transfer, this shifts the responsibility for the
- access,
- authorization to the data and
- processing of the data
from the application development to the provider and hence ultimately, the actual owner of the data.
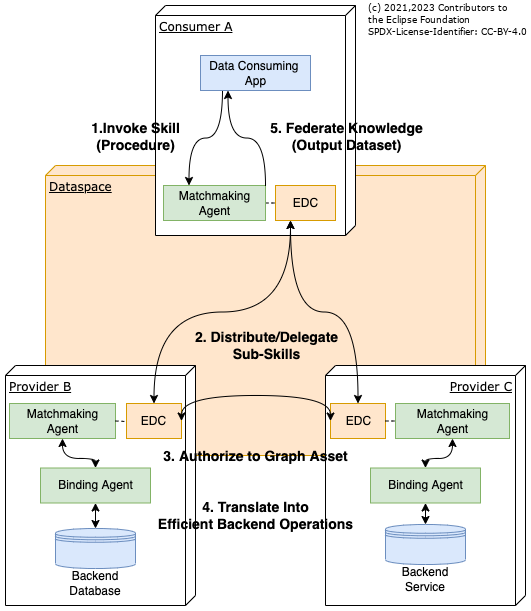
App
The App in the figure serves the consumer by gathering, analyzing, and presenting the knowledge about business questions such as: How much of a certain material can be found in a specific vehicle series? It is assumed that the data which is needed to answer such questions is distributed over the network and cannot be found at one central place.
Skill
To help collecting the data over the network, Skills are introduced. A Skill is a pre-formulated query (or: procedure) with limited scope such as: List all vehicle series that contain material produced in location. The Skill is used to access all federated data instances via the tenant (=authentication and authorization scope) of the caller.
A skill receives input in the form of a data set (we use a JSON notation in the following example):
[{"material":{"type":"literal","value":“Rubber”},"location":{"type":"literal","value":“Phuket”}}]
which drives the control flow, the filtering and aggregating of the information, and finally producing an output data set, for example:
[
{"series":{"type":"uri","value":"OEM#4711"},"oem":{"type":"uri","value":"OEM"},"weightKg":{"type":"literal","datatype":"http://www.w3.org/2001/XMLSchema#float",”3.2”}},
{"series":{"type":"uri","value":"EMO:0815"},"oem":{"type":"uri","value":"EMO"},"weightKg":{"type":"literal","datatype":"http://www.w3.org/2001/XMLSchema#float",”1.4”}}
]
Semantic Model
In order to obtain the correct results in a federated system, all the participants of the skill execution need to have common understanding (Semantic Model, in KA this is mechanized by a Federated Catalogue based on the Web Ontology Language OWL) over the vocabulary (Data Model, in KA this is represented generically by sets, i.e., graphs of Resource Description Framework RDF triples). A guideline for how this vocabulary should be formulated can be found here.
Relying on these conventions, a Skill executor can calculate which Providers are able to contribute or yield the necessary information in which sequence such that the resulting distributed operation will be performant.
Matchmaking Agent
This coordinating job is taken over by the Matchmaking Agent, an endpoint that is mandatory for any KA-enabled Dataspace Participant. For that purpose, the Matchmaking Agent supports the SPARQL specification with the effect that the dataspace can be traversed as one large data structure. Hereby, the Consumer-Side Matchmaking Agent will – as driven by the builtin federation features of SPARQL - interact with the KA-enabled EDC in order to negotiate and perform the transfer of Sub-Skills (=SPARQL Contexts) to other Dataspace Participants. See the Knowledge Agents SPARQL API for detailed information.
In turn, upon successful transfer of the Sub-Skill, the Provider-Side Matchmaking Agent(s) will be activated by their respective EDC. The precondition for this activation is that the Provider EDC first needs to offer a so-called Graph Asset.
Graph Assets
are a variant of ordinary Data Assets in the Catena-X EDC Standard; while Data Assets typically refer to an actual backend system (e.g., an Blob in an Object Store, an AAS server, a REST endpoint), Graph Assets introduce another intermediary instance, the so-called Binding Agent.
Binding Agent
Simply put, the Binding Agent is a restricted version of the Matchmaking Agent (which speaks a profile, i.e., a subset of SPARQL specification, see the ANNEX) which is just focused on translating Sub-Skills of a particular business domain (Bill-Of-Material, Chemical Materials, Production Sites, etc.) into proper SQL- or REST based backend system calls. This scheme has several advantages:
- For different types of backend systems, business domains and usage scenarios, different Binding Agent implementations (Caching Graph Store, SQL Binding Engine, REST Binding Engine) can be switched-in without affecting both the shared dataspace/semantic model and the mostly immutable backend systems/data models as well.
- Access to the backend systems can be optimized by JIT compilation technology.
- The same backend system/data model can be used in various Graph Assets/Use Cases and different roles and policies.
- Access to the backend system is decoupled by another layer of security, such that additional types of policies (role-based row-level and attribute-level access) can be implemented in the interplay of Matchmaking and Binding Agents.
- There is a clear distinction between advanced graph operations (including type inference and transitive/recursive traversal also via EDC) on the Matchmaking Level and efficient, but more restricted and secure graph operations on the Binding/Data Level.
Federated Catalogue
As mentioned earlier, essential for the realization of the idea is the creation, governance and discoverability of a well-defined semantic catalogue, which forms together with the data a Federated Knowledge Graph. In this context, the definition of a Knowledge Graph (KG) as "a multi relational graph composed of entities and relations which are regarded as nodes and different types of edges, respectively" is extended with aspect of federation. This KIT defines a Federated KG as a KG where entities and relations reside physically distributed over multiple systems connected through a network and a common query language. This KIT defines semantic metadata as structural information to scope the entities and relations of the KG based on ontological principles. This is the agreement, necessary for the successful interplay of the distributed parties within the data space.
Abilities
To summarize, the Knowledge Agent standard shall achieve the following abilities:
- the ability to define well-formed and composable computations/scripts (skills) which operate over various assets of various business partners.
- the ability to invoke and dynamically distribute these (sub-)skills over the relevant partners/connectors using an extensible agent interface.
- the ability to safely provide data and service assets via appropriate agent implementations which "bind" the skill to the backend execution engines (rather than mapping data).
- the ability for an agent/connector/business partner to decide
- whether to hide particular data and computations inside a sub-skill
- whether to delegate/federate particular computations/sub-skills to other agents
- whether to migrate or clone an agent/asset from a partner
- the ability to describe data and service assets as well as appropriate federation policies in the IDS vocabulary in order to allow for a dynamic matchmaking of skills and agents.
- the ability to define domain/use case-based ontologies which form the vocabulary used in the skill definitions.
- the ability to visualize and develop the ontologies and skills in appropriate SDKs and User Experience components.