Adoption View
![]()
Agents KIT
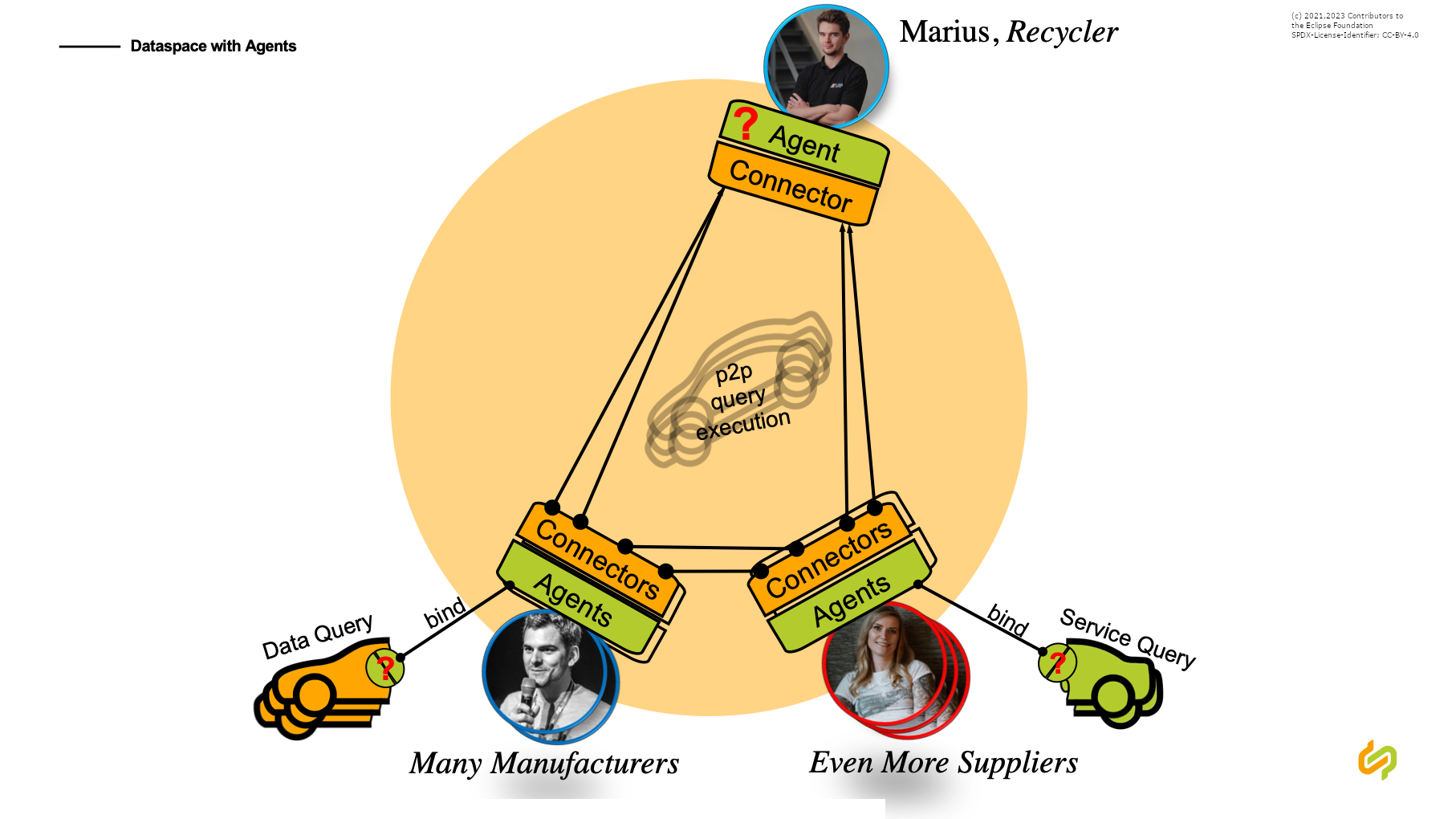
Federated queries over the whole data space.
Vision & Mission
This KIT specifies a semantically-driven and state-of-the-art compute-to-data architecture for (not only) automotive use cases based on the best GAIA-X, W3C and Big Data practices.
Specifications & Standards
This KIT refers to standards for invoking and performing semantic computations (inferences or skills) based on normalized and linked data representations (knowledge graph described as RDF triples) over the dataspace.
Leveraging existing standards such as IDS, RDF, SparQL, OWL, SHACL & EClass, linked data and corresponding skills may be provisioned, consumed, federated and visualised across the complete dataspace (technically) and hence the complete supply chain (business-wise).
Skills can be described in tractable sub-languages of well-known declarative syntaxes, such as SparQL (in the future maybe also: GraphQL and SQL).
Our specifications have been published as Catena-X e.V. Standards:
- CX-0084 Federated Queries in Dataspaces (V1.2.0)
- CX-0067 Ontology Models to Realize Federated Queries in Catena-X (V1.1.0)
Implementations
This KIT aggregates open-source reference implementations of these standards to Tractus-X in particular extending the Connector KIT
These components are called agents) because they (semi-)actively negotiate and collaborate with each other (via so-called graph and skill assets) over the dataspace in order to derive higher-level semantic knowledge from the plain, isolated data.
Knowledge agents introduce an ecosystem of efficient services (for data handling, compute, skill orchestration and frontend components) where an optimal matchmaking between those services needs to be reached.
This KIT also defines bridges to other digital twin approaches, such as AAS (Asset Administration Shell), such that data and service provisioning into multiple use cases will be as effortless as possible.
Our Implementations can be accessed as Eclipse Tractus-X Repositories:
- Agent Plane(s) for EDC (KA-EDC) see also KA-EDC Operation View
- Binding Agent(s) for Providers (KA-RI) see also KA-RI Operation View
- Agent Bridges for AAS (KA-AAS) see also KA-AAS Operation View
Support
The team supports use case consumers, app developers, data providers, service providers and IT/domain consultants in order to operate as economically and well-informed as possible by giving them first-class tools, documentation and feedback. For that purpose, please meet us in the Tractus-X Community.
Business Value
The Agents KIT is the best fit for use case and applications which
- do not focus on exchanging/analyzing static assets between two peers in the supply chain, but instead require crawling over a whole dynamic branch of the supply tree.
- do not focus on gaining predefined schemas of digital twins, but need to perform complex search and aggregations over both catalog and assets.
- require rapidly changing and extensible logic that should reuse existing assets which have already been built for other use cases.
- need to securely extract & aggregate knowledge from large amounts of assets and/or large assets.
As a dataspace participant, adopting the Agents KIT will
- allow you to easily bind your own data and services into the relevant use cases and applications
- give you the means to integrate your company-internal data sources with the dataspace as one big knowledge graph
The following advantages play an important role.
Democratization of added value service design for data spaces
Currently, the development of full-scale Apps to address use cases for cross-company exchange requires a lot of development effort. By proceeding this way, addressing new business problems or fast prototyping of solution ideas are not straightforward to achieve. Thus, the idea of a fast-growing ecosystems based on data exchange between companies is at risk. KA introduces Skills as a new concept to support query of data spaces with small effort. A new Skill can be developed in few days in comparison to weeks or months for app development. In this context it is aimed that data consumers are able to create skills by themselves based on their very specific business demand.
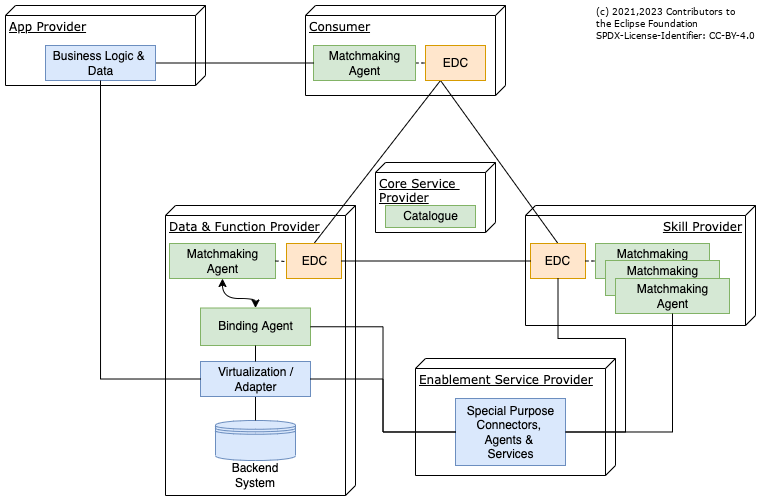
In addition, a third party in addition to Consumer and (Data, Function) Provider can be imagined: The Skill provider (see Figure 3). Similar to an App Provider, the Skill Provider develops queries to address various business problems. Developed Skills can be offered as Skill Assets over the dataspace and in the Marketplace, quite similar to the existing Services and Apps.
It is also possible to combine Skill and App development (by using Skills as stored procedures in the App framework). By following this approach App developers can concentrate on frontend optimization and usability of the app while the skills deliver the business relevant information.
Custom Search
Based on the skill concept, mighty search functionalities can be realized by utilizing the KA approach. SPARQL is already a common standard to browse large data catalogues (e.g. Wikidata). By utilizing this principle, it becomes possible to search for objects which are unknown at the beginning of the search (similar to Google). This advantage is important since comparable twin-based approaches for the semantic layer require a specific ID to find an object.
Widespread Standard
Isn't this a proprietary approach?
The underlying API, protocols, standards and technologies are first-class citizens of the official Gaia-X & W3C Semantic Web portfolio. These techs have been already adopted globally for a plethora of domains, use cases and derived (Open Source & commercial) projects. Using these approaches will give you a competitive advantage which is even independent of the concrete dataspace instance/application that you are targeting at.
No Redundancy
Is this a replacement to the existing Aspect Meta Model (BAMM/SAMM) & Asset Administration Shell (AAS) approach?
Agent technology is a complement that means that both approaches can be deployed in co-existance.
There will be some use cases (large interconnected datasets, ad-hoc querying, inference of derived knowledge) which enfavour the knowledge agents approach, others (simple access to already identified remote twins) will more adequately stay with the BAMM/SAMM & AAS approach.
For the data providers, it will be easy to mount their artifacts (files, data source partitions, backend interfaces) under both types of assets (submodels, graphs). We provide bridging technology for that purpose.
For the app developers it will be easy to use both SDKs over a single consumer connector and even interchange the identifiers/IRIs.
For the modellers, there is only a loose coupling between a protocol-independent, inference-agnostic data format description, such as BAMM/SAMM, and a protocol-binding, but data-format independent inference/semantic model, such as OWL-R. We expect tools to generate at least the latter from ubiquitous Excel/Tabular specifications. We could also imagine a kind of OWL-R to BAMM/SAMM embedding (but not vice versa) once this is needed by a use case.
Data Sovereignity & Enhanced Security
One of the key requirements for dataspaces is to guarantee that data is only shared willingly and subject to specific terms and conditions of respective data providers. One core component to support definition and negotiation of contracts and policies is the Eclipse Dataspace Connector (EDC). Nevertheless, the way how data is processed via a semantic layer also contributes to data sovereignty. KA follows a strict compute to data approach. Thus, by design only computation results are shared instead of copying all data relevant for this computation (e.g. submit only weight information instead of geometry and material information). Furthermore, by utilizing data models based on ontologies definition of access rights can be made up to a high level of granularity (attribute level).
Isn't it inherently insecure to let arbitrary Dataspace tenants invoke ad-hoc computations in my backend?
First, these are not arbitrary tenants, but access is only given to business partners with whom you have signed contracts (and who appear in certain roles there). A Skill request from a non-authorized chain of computation would not be able to enter your backend at all.
Furthermore, you would not expose your backend directly, but rather introduce a virtualization layer between the Agent and your data source. This introduces another (role-based) security domain by appropriate sub-schemas and filters. So different contracts can be mapped to different security principals/data views in the backend.
This KIT does not introduce arbitrary (turing-equivalent, hence undecidable) ad-hoc computations, but the SPARQL standard introduces a well-defined set of operations whose effects and consequences can be checked and validated in advance (hypervision).
Finally, the team is investigating a form of differential privacy which introduces noise between your data source and its graph representation such that original values can be effectively hidden from the reporting output.
Easy Deployment
Doesn't this impose additional burdens to the dataspace participants?
For data consumers, there is virtually nothing to do. All they have to care for is to add an Agent-Enabled data plane to their connector (or even use our Agent Plane as a fully-blown replacement for the Http/AmazonS3 standard of Tractus-X).
For smaller data and skill providers, there will be the possibility to host non-critical data directly through the storage facilities of the Agent Plane.
For all others, they will employ techniques for data virtualization anyway to scale and shield their critical data. That is where the binding agents as one additional container/layer that is declaratively described (not: programmatically) come into play.
Great Scalability
Utilization of dataspaces for exchanging complex product- or production data usually involves transfer of large datasets. If for example an automotive OEM wants to access information of their car fleets ranging from hundreds to millions of cars, the dataspace still needs to provide required data in short time without risking too much load on the network. Thus, the outlined approach is based on efficient federated SPARQL queries which only transport computation results across the network in contrast to full datasets (compute to data). Further potentials for streamlining performance are for example parallelized EDC contract negotiations and efficient delegations between suppliers.
How could such a scheme be efficient at all
Our technology has been thoroughly developed, tested and piloted over the years 2022 and 2023. One key component is the ability of any Agent to delegate a part of its work to other Business Partners/Agents and hence to bring the computations close to the actual data. This delegation pattern has several very nice properties:
- Delegation is dynamic based on the supply chain(s) that are described in the actual data. So the actual computation chain optimizes with the data.
- Delegation is parallelized in the sense that several suppliers are requested simultaneously. Latency is hence minimized.
- Delegation may be opaque from the consumer view if contracts require so.
Use Cases
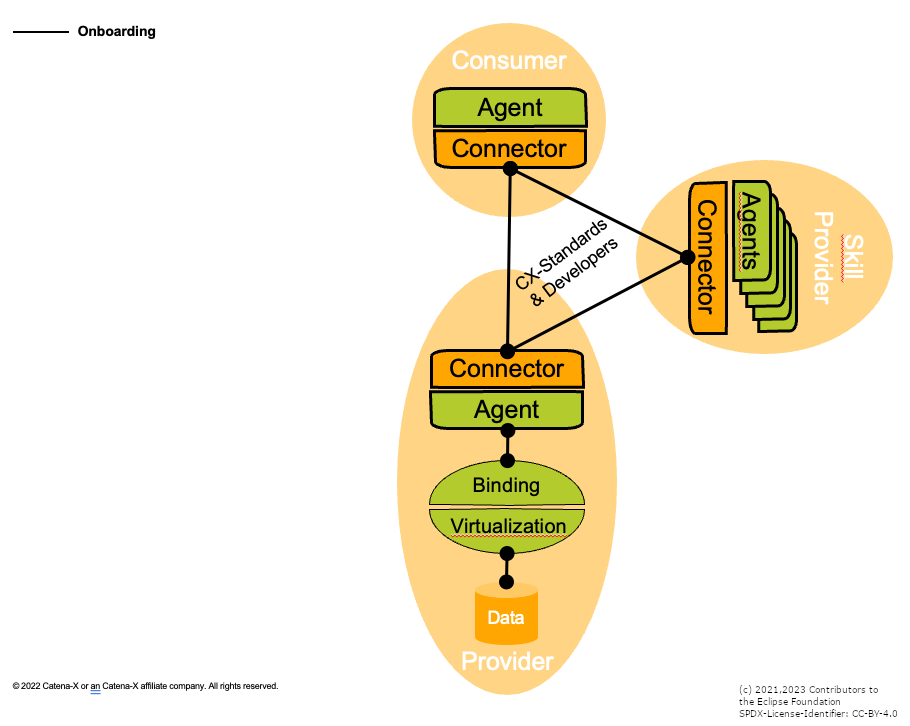
The Agents KIT is the basis for other, use-case specific Agent-enabled KITs, services and applications, such as the Behaviour Twin KIT.
It distinguishes between Dataspace Participants and other parties (who support the Dataspace Participants).
Dataspace Participants
The following stakeholders should deploy modules/artifacts of the Agents Kit. In particular, each Dataspace Participant needs an Agent-Enabled Connector.
Consumer
Any party who wants to use data and logic using Agent Technology (for example by employing Agent-Enabled Applications or Services), such as a Recycling Company or a Fleet Manager
Provider
The Agents KIT distinguish Providers whether they want to publish data or logic using Agent Technology
Data Provider
Any party who provides data (for example by a backend database or other Agent-enabled Applications or Services), for example an Automotive OEM (original equipment manufacturer)
Function Provider
Any party who provides proprietary functions (for example by a REST endpoint or other Agent-enabled Applications or Services), for example a Tier1 Sensor Device Supplier
Skill (=Compute) Provider
Any party who provides compute resources and/or procedural logic (for example by a server or other Agent-enabled Applications or Services), for example a Recycling Software Specialist
Core Service Provider
Any party offering ontology models (semantic/ontology hub) or federated catalogues, for example an Operating Company
Additional Stakeholders
The following stakeholders should interface or implement modules of the Agents Kit.
Business Developer
Any party who publishes an Application, Standard or KIT based on Agent Technology on behalf of a Dataspace Participant (e.g. a Fleet Monitor, an Incident Reporting Solution, a Telematics KIT)
Enablement Service Developer
Any party who offers ready-made artifacts, packages and managed services assisting Dataspace Participants/Applications to process data using Agent technology (e.g. a Graph Database, a Virtual Graph Binding Engine, an EDC Package)
NOTICE
This work is licensed under the CC-BY-4.0.
- SPDX-License-Identifier: CC-BY-4.0
- SPDX-FileCopyrightText: 2021,2024 T-Systems International GmbH
- SPDX-FileCopyrightText: 2021,2023 Mercedes-Benz AG
- SPDX-FileCopyrightText: 2022,2023 Bayerische Motoren Werke Aktiengesellschaft (BMW AG)
- SPDX-FileCopyrightText: 2021,2023 ZF Friedrichshafen AG
- SPDX-FileCopyrightText: 2021,2023 SAP SE
- SPDX-FileCopyrightText: 2022,2023 Contributors to the Eclipse Foundation