Detailed Architecture
Agents KIT
![]()
Arc42 for federated queries over the whole data space.
For more information see
- Our Adoption guideline
- The High-Level architecture
- The Ontology modelling guide
- An API specification
- The Layers & Modules Architecture
- Our Reference Implementation
- The Deployment guide
Introduction and Goals
The main objective concerning the approach described in this section is to create a state-of-the-art compute-to-data architecture for automotive use cases (and beyond) based on standards and best practices around GAIA-X and W3C. To reach this aim, full semantic integration, search and query with focus on relations between entities and data sovereignty is focused. In contrast to a simple file-based data transfer, this shifts the responsibility for the access, authorization to the data and processing of the data from the application development to the provider and hence ultimately, the actual owner of the data. To achieve this aim, the Knowledge Agent standard shall achieve the following abilities:
- the ability to define well-formed and composable computations/scripts (skills) which operate over various assets of various business partners.
- the ability to invoke and dynamically distribute these (sub-)skills over the relevant partners/connectors using an extensible agent interface.
- the ability to safely provide data and service assets via appropriate agent implementations which "bind" the skill to the backend execution engines (rather than mapping data).
- the ability for an agent/connector/business partner to decide
- whether to hide particular data and computations inside a sub-skill
- whether to delegate/federate particular computations/sub-skills to other agents
- whether to migrate or clone an agent/asset from a partner
- the ability to describe data and service assets as well as appropriate federation policies in the IDS vocabulary in order to allow for a dynamic matchmaking of skills and agents.
- the ability to define domain/use case-based ontologies which form the vocabulary used in the skill definitions.
- the ability to visualize and develop the ontologies and skills in appropriate SDKs and User Experience components.
See also the KIT Introduction section and The High-Level Architecture.
Constraints
The Knowledge Agents Architecture is based on the Catena-X Dataspace Architecture with a specific focus on the Eclipse Dataspace Connector (EDC). It integrates with Catena-X Portal/Core Services & Identity Management principles and supports the typical interaction models as required by Catena-X Use Cases, such as
- Traceability with Focus on Low-Volume Bills-Of-Material Data and Deep Supply Chains with One-Up and One-Down Visibility
- Behaviour Twin with Focus on High-Volume Telematics Data and Flat and Trustful Supply Chain
Furthermore, on the vocabulary/script level it utilizes and extends well-defined profiles of W3C Semantic Web Standards, such as OWL, RDF, SHACL, SPARQL.
Context and Scope
The standard is relevant for the following roles:
- Business Application Provider
- Enablement Service Provider
- Data Consumer
- Data Provider
The following Catena-X stakeholders are affected by Knowledge Agent approach
Business Application Provider: Applications that use KA technology on behalf of a Dataspace Participant (e.g. a Fleet Monitor, an Incident Reporting Solution).
Enablement Service Provider: Services to assist Dataspace Participants/Applications in processing data based on KA technology (e.g. a Graph Database, a Virtual Graph Binding Engine, an EDC Package). As a second path, Companies are addressed that want to provide compute resources (for example by a server or other KA-enabled Applications or Services) based on instances/configurations of KA-enabled EDC Packages, for example a Recycling Software Specialist
Data Consumer: Companies that want to use data and logic (for example by KA-enabled Applications or Services) based on instances/configurations of KA-enabled EDC Packages, such as a Recycling Company or a Tier-2 Automotive Supplier
Data Provider: Companies that want to provide data (for example by a backend database or other KA-enabled Applications or Services) based on instances/configurations of KA-enabled EDC Packages, for example an Automotive OEM. Companies that want to provide functions (for example by a REST endpoint or other KA-enabled Applications or Services) based on instances/configurations of KA-enabled EDC Packages, for example a Tier1 Sensor Device Supplier
Content-wise the following capabilities of Catena-X are addressed:
- Query and Search (Basic Mechanism, Integration in User Experiences)
- Services for making use of various federated data sources being part of a data space (Data & Function Provisioning, Logic Development & Provisioning)
- Semantic Modelling
- Publishing, Negotiation, Transfer Protocols and Policy Enforcement via IDS (EDC) connector
Solution Strategy
Knowledge Agents regards the peer-to-peer Dataspace as one large (virtual) knowledge graph.
A graph, because the representation of data as a set of Triples (Outgoing-Node = Subject, Edge = Predicate, Receiving-Node = Object) is the highest form of normalization to which all other forms of structured data can be abstracted.
Virtual, because this graph is not centrally instantiated in a dedicated database, but it is manifested by a computation (traversal) which jumps from node to node (and hereby: from the sovereignity domain of one business partner to the another one including taking over authentication and authorization information).
Knowledge because computations and graph contents are not arbitrary, but share common meta-data (again in the form of a graph interlinked with the actual instance graph) such that the vocabulary (at least: edge names) is standardized and computations can be formulated (offered) independent of the data.
To reach that metaphor, the Knowledge Agents Architecture uses the following specifications, some of which are standard-relevant:
- A general description language based on the Resource Description Framework (RDF)
- A Meta-Model defined by OWL-R
- A platform Ontology (consisting of several domain ontologies) as the Semantic Model
- A description of graphs (=graph assets) which contain instance data for the Semantic Model (or: use-case driven and role-driven subsets thereof) and which may be described as SHACL constraints
- A query language to traverse the graphs in SPARQL and store these queries as skills (=skill assets) in the database
Non-standard relevant, but provided as a best practice/blueprint architecture are
Bindings for relational and functional data
SQL- and REST-based Virtualizers which bridge public Dataspace Operations with internal/private backend systems/data sources.
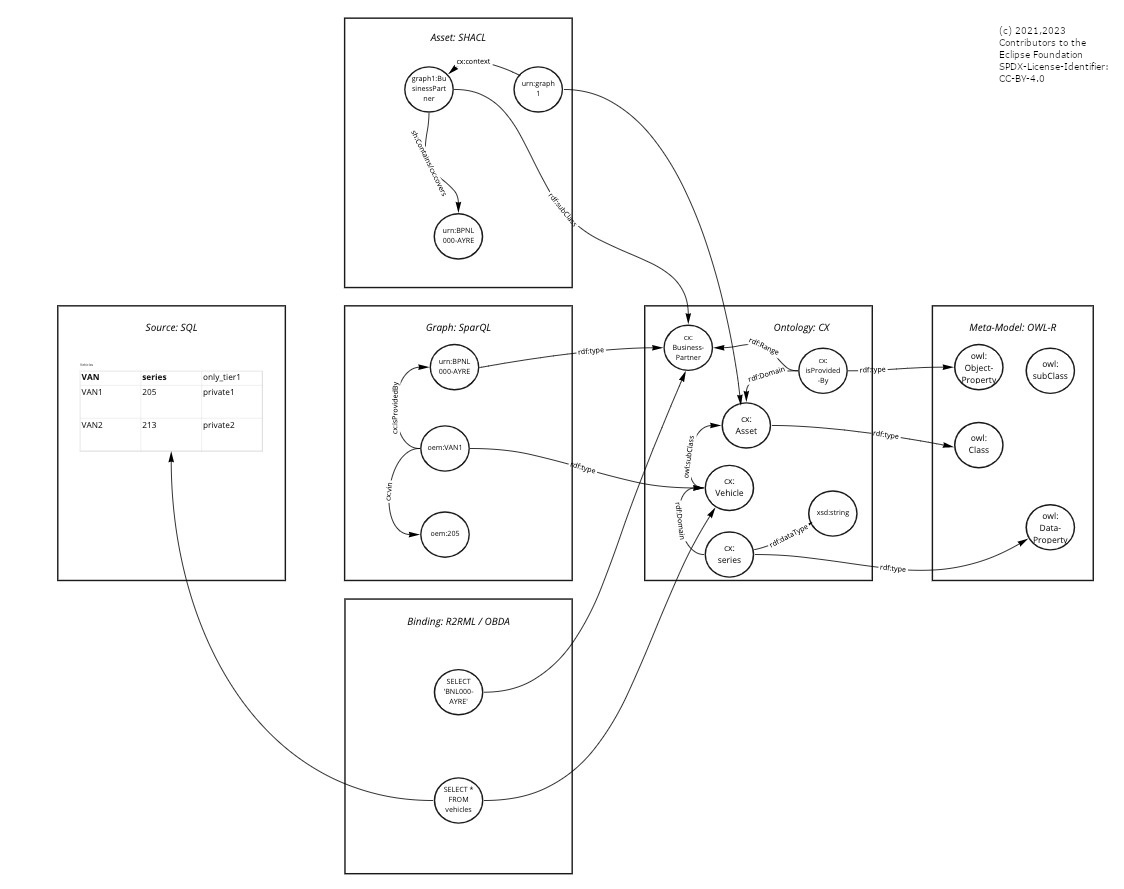
Knowledge Agents regards the peer-to-peer Dataspace as one large federated execution engine.
Federation means distributed that is there is no central endpoint/resource which controls the computation, but the execution may be entered/triggered on any tenant and uses a scalable set of resources which are contributed by each participant.
Federation means independent in that there is no central authentication/authorization regime, but the computation is validated, controled and (transparently) delegated by decentral policies as given/defined be each particpant.
See also High-Level Architecture.
Building Block View
See chapter Layers & Modules
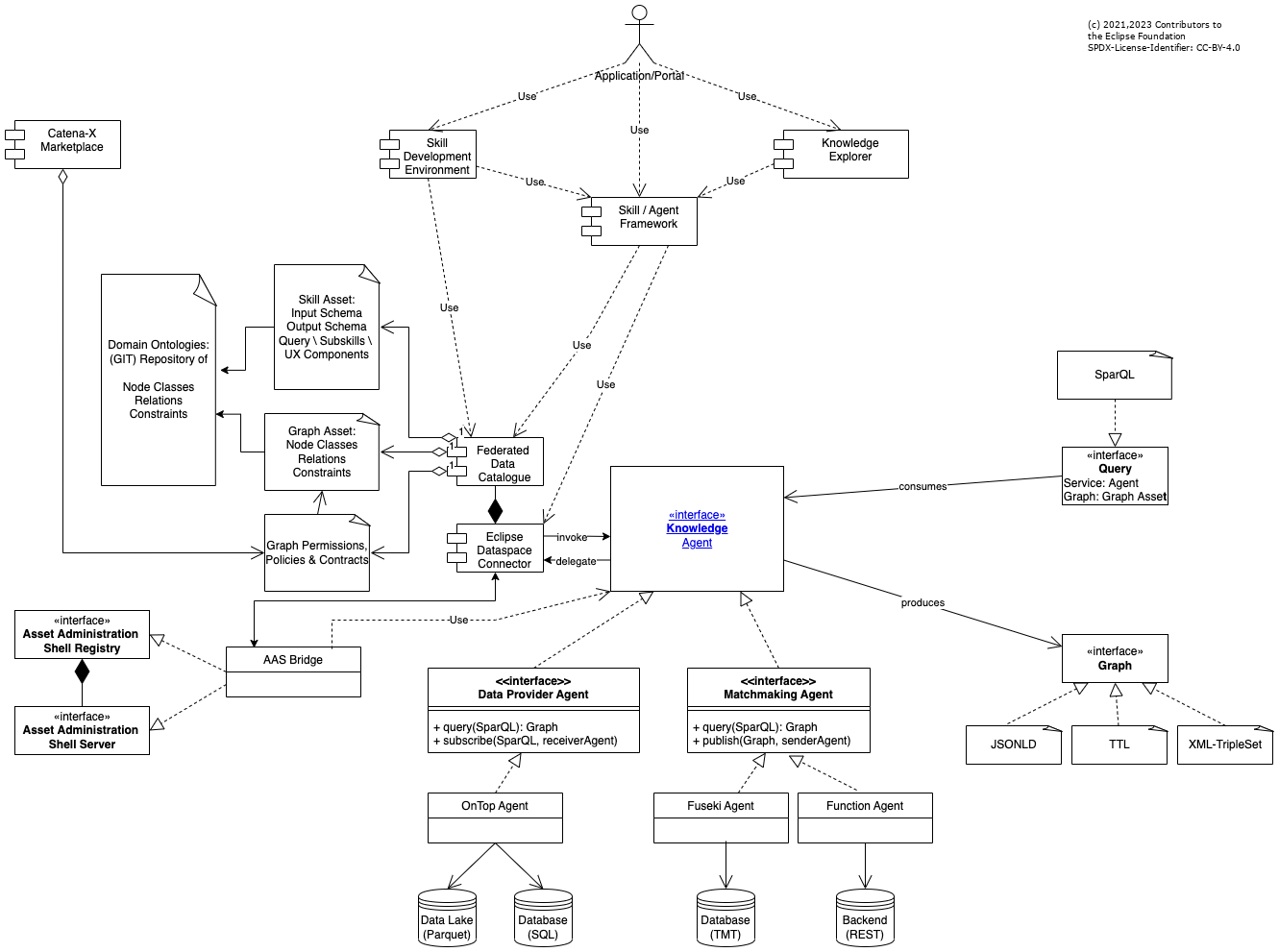
Runtime View
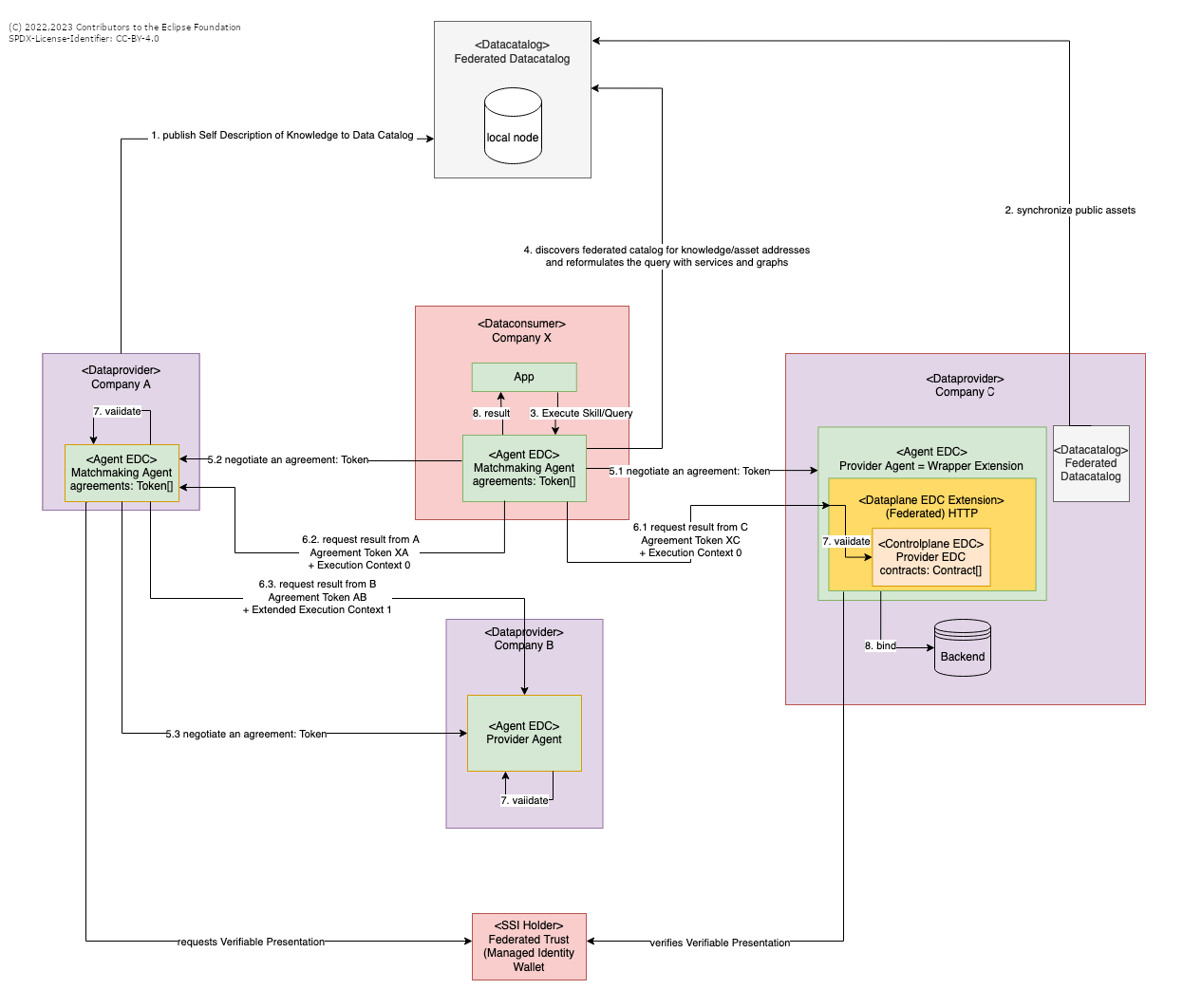
Sequence of actions:
- A data provider provides a self description of the piece of knowledge he likes to provide including the terms of conditions in his own data catalogue (Although the diagram depicts only one single instance of the Federated Datacatalog, each EDC of each participant (Provider or Consumer) runs a Datacatalog instance. Beween those synchronisation takes place)
- Graph assets describe means of domain ontologies the
- node classes
- relations (edges between nodes)
- constraints on nodes and relations (temporal, value ranges, regex patterns, ...)
- constraints on the queries/skills that may be executed on the graph (e.g. allowed and denied network connections)
- Graph policies will restrict the following operations on graphs (based on nodes and edges, given an execution context)
- selection
- traversion
- storage
- manipulation
- deletion
- delegation
- Graph assets describe means of domain ontologies the
- A data provider marks particular graph assets as being visible in the federated data catalog. The federated data catalogues of the federated companies/EDCs will be automatically synchronized.
- Any consuming app can employ an agent with a suitable skill/query (which can be provided locally or as a remote asset, too)
- The agent will match the requirements in the skill with the offers in the federated data catalog to fill in the endpoints and usage policies from the self descriptions.
- Agreements (between XA (5.1), XC (5.2), eventually between AB (5.3)) have to be set up in such a way that the corresponding agents are allowed to communicate through the data plane.
- The agent delegates a sub-query/sub-skill to the respective knowledge owners (data provider C: 6.1, A: 6.2 and B: 6.3) via an instance of EDC. It annotates the sub-queries with a call context containing the EDC/agent calling sequence and the other assets to be joined with the result data. 6.3 shows that an agent can decide to delegate further down the line
- The data plane will validate the calling context together with the claims inside the agreement token.
- The agent executes the actual query by mapping to a backend data system and finally providing the result to the app
Just as the Federated Datacatalog is a multi-instance-synchronised component, also the Federated Trust is an instance running on each EDC. All Federated Trust instances are synchronised with each other within the referring EDC ecosystem.
Deployment View
See chapter Deployment.
(C) 2021 Contributors to the Eclipse Foundation. SPDX-License-Identifier: CC-BY-4.0